


Introduction
Gambling disorder is a behavioral addiction that can have detrimental effects on quality of life including personal finances, work, relationships and overall mental health (; ). Despite these negative consequences, many gamblers are motivated to continue to play, and praise the temporary excitement and pleasure (). Accumulating evidence suggests similarities of gambling disorder and substance-use-disorders both on behavioral, cognitive and neural levels (; ; ; ; ). In light of these similarities, the fifth edition of the “Diagnostic and Statistical Manual of Mental Disorders” categorizes gambling disorder in the category of “Substance-related and Addictive Disorders” (). In contrast to substance-use-disorders, differences in behavioral and/or neural effects between gamblers and controls are unlikely to be confounded by chronic or acute drug effects (; ; ). Gambling disorder has thus been termed a “pure addiction” ().
Recently, categorical definitions of mental illness have increasingly been called into question. The National Institute for Mental Health of the United States proposed the Research Domain Criteria (RDoC) to foster characterization of the dimensions underlying psychiatric disorders. According to this approach, research in cognitive science should focus on the identification of continuous neuro-cognitive dimensions that might go awry in disease, i.e. trans-diagnostic markers (). Here we focus on two promising candidates for such trans-diagnostic processes that are affected across a range of psychiatric conditions, including gambling disorder: temporal discounting, i.e. the devaluation of delayed rewards (; ; ), and model-based (MB) control during reinforcement learning (). MB control refers to computationally more expensive goal-directed strategies that utilize models of the environment, contrasting with model-free (MF) control that operates on stimulus-response associations (; ; ; ).
Steep discounting has been consistently observed in substance use disorders and gambling disorder (; ; ; ). Moreover, alterations in temporal discounting occur in a range of other disorders, including depression, bipolar disorder, schizophrenia and borderline personality disorder (), underlining the trans-diagnostic nature of this process. Changes in the contributions of MF and MB control have likewise been reported across multiple disorders, including gambling disorder (), schizophrenia (), obsessive compulsive disorder () and substance use disorders (). Reduced MB control is also reflected in sub-clinical psychiatric symptom severity ().
Addiction is known to be under substantial contextual control. Addiction-related cues and environments are powerful triggers of subjective craving, drug use and relapse. Incentive sensitization theory (; ) provides a theoretical framework that links such effects to a highly sensitized dopamine system that responds to drugs and addiction-related cues. Increased responses of the dopamine system to addiction-related cues (“cue-reactivity”) has been consistently observed in neuroimaging studies of human addicts (; ), and there is evidence that trans-diagnostic behavioral traits are likewise under contextual control. For example, regular gamblers discount delayed rewards substantially more steeply when tested in a gambling-related environment as compared to a neutral environment (). Similar effects have been observed in laboratory tasks that include gambling-related cues (; ; ) but whether other putative trans-diagnostic traits such as MB control are under similar contextual control is unclear. Beyond, it is unclear whether gambling severity or maladaptive control beliefs () modulate such effects.
Though rarely examined in naturalistic settings, contextual effects on trans-diagnostic dimensions of decision-making are of substantial clinical and scientific interest. Settings with high ecological validity might provide more informative insights into the central drivers of maladaptive behavior than laboratory-based studies (). If such trans-diagnostic traits are further exacerbated in e.g. addiction-related environments, this could constitute a mechanism underlying the maintenance and/or escalation of maladaptive behavior. Second, traits such as temporal discounting can be modulated (; ; ) and could thus serve as a potential treatment target ().
The present pre-registered study thus had the following aims. First, we aimed to replicate the findings by Dixon et al. (), who observed increased temporal discounting in gambling-related environments in regular gamblers, compared to neutral environments. Second, we extended their approach by including a modified version of the prominent 2-step sequential decision task () to test whether model-based control of behavior is likewise under contextual control. Reduced model-based control has been linked to a range of psychiatric conditions (see above) including gambling disorder (). Third, we directly tested for associations of contextual effects with gambling symptom severity and working memory capacity. Finally, our tasks allowed for comprehensive computational modelling of choices and response time (RT) distributions. Analyses of reinforcement learning and decision-making have recently been shown to substantially benefit from an incorporation of RTs (; ; ; ; ) via the application of sequential sampling models such as the drift diffusion model (DDM) (). Such analyses yield additional insights into the latent processes underlying decision-making () and can improve parameter stability (). To account for these recent developments, we complemented our pre-registered analyses with additional analyses of temporal discounting and reinforcement learning drift diffusion models (RLDDM).
Methods
Preregistration
This study was preregistered via the open science framework (https://osf.io/5ptz9/). We deviated from the pre-registered study design in the following ways. First, it was initially planned to use a lab-setting for the neutral (non-gambling) testing environment. However, this was changed following pre-registration to a café, which we felt was more similar to the gambling environment in terms of the presence of social cues and the overall level of distraction. Second, we initially aimed to include gamblers fulfilling at least one DSM-5 criterion for gambling disorder. This was adjusted to a stricter inclusion criterion of at least three DSM-5 criteria. Due to high correlation between rotation- and operational span during piloting we decided to remove the rotation span task from our working memory assessment. All of these changes were implemented before testing began. Further, to account for recent developments in computational modelling we made two changes to our pre-registered computational analyses. First, we tested several alternative model formulations and performed posterior predictive checks for the standard hybrid model using another dataset. This resulted in some changes in model formulation close to Otto et al. () and as proposed by Toyama et al. (, ). All of these changes were applied before data analysis (for details of model specification see methods section).
Second, to account for recent developments in computational modelling we also complemented the standard softmax model analysis with additional analyses of RT distributions via temporal discounting and reinforcement learning DDMs (; ; ; ; ). As a model-free measure of intertemporal choice we used a logistic regression model instead of computing the area under the empirical discounting curve (AUC) (). All of these changes were applied prior to data analysis (for details of model specification see methods).
A-priori sample size was calculated based on results by Dixon et al. () observed an effect size of d = .5 for the effect of gambling environments on temporal discounting in regular gamblers. Power analysis () yielded a minimum sample size of n = 26 with alpha error probability of .05 and power of .80. We then pre-registered a target sample size of n = 30.
Participants
Participants were recruited via advertisements posted online and in local gambling venues. First, they were screened via a telephone interview to verify that they show evidence for problematic gambling behavior, with a primary gambling mode of electronic slot machines. Further inclusion criteria were age in the range of nineteen to fifty, no illegal drug use, and no history of neuropsychiatric disorders, current medication or a history of cardiovascular disease. The ethics committee of the University of Cologne Medical Center approved all study procedures.
Forty-two participants were then invited to a first appointment, where they provided written informed consent and completed a questionnaire assessment and a set of working memory tasks (see section on background screening below). Five participants dropped out during or after the first appointment. Four additional participants were excluded after the first appointment because they fulfilled less than three DSM-V criteria for gambling disorder. Two participants dropped out after the first experimental testing session, and one participant was excluded because he fell asleep twice during one testing session. Due to technical problems, we obtained complete datasets for thirty participants for the intertemporal choice task and twenty-nine participants for the 2-step task, with twenty-eight participants overlapping.
Overall procedure
Participants were invited to three appointments. At the first appointment (baseline screening; see below) participants were invited to our lab and performed a questionnaire assessment and four working memory tasks. Participants were randomly assigned to one of the two locations (café vs. casino) on the first experimental appointment (pseudorandomized location [first session neutral or gambling] and task-version; see section on tasks below). We label the café environment as neutral because no gambling associated cues were present. In both locations, the delay discounting task was completed first, followed by the 2-step task. Appointments were made on an individual basis but spaced within 7+-2 days and around the same time of day +- 2 hours. The café environment was an ordinary café serving non-alcoholic drinks and snacks and furnished with 10 tables and approximately 50 m2 of size. Testing occurred while the café was in business as usual and experimenter and participant sat at a table next to a wall to assure some privacy. The café was usually moderately attended and testing occurred at the same spot for all participants, with only a few exceptions when this seat was taken. The gambling environment was a common slot-machine venue operated by a German gambling conglomerate. The experimenter and participant were seated at a table placed next to a wall in sight of the electronic gaming machines (EGMs). In total there were four EGMs in direct sight of the participant and a total of ten in the room (hidden by eye protection walls). The density of gambling related cues varied as a function of people playing at EGMs, background sounds e.g. sounds of winning or money dropping were all depended on regularly customers. However, in nearly all cases other people were playing EGMs in direct sight of the participants. The experimenter was granted permission to conduct research in two local gambling venues. Two chairs and a table to use for the experimental session were provided. In both locations, subjects were placed in such a way that neither experimenter nor customers could view their screen. Both tasks ran on a 15inch Laptop using the Psychopysics toolbox () running in Matlab (The MathWorks ©).
Background screening
Participants filled out a battery of questionnaires regarding gambling related cognition (GRCS) () and symptom severity (DSM-5;KFG,SOGS) (; ; ), demographic evaluation and standard psychiatric diagnostic tools (see Supplemental Tables S1 and S2).
We assessed working memory capacity using a set of four working memory paradigms. First, in an Operation Span Task () subjects were required to memorize a sequence of letters while being distracted by math-operations. Second, in a Listening Span Task (adapted from the German version of the Reading Span Test developed by van den Noort et al. () subjects were required to listen to a series of sentences and had to recall the last word of each sentence. Last, subjects performed two different versions of a Digit Span Task (forward/backward) that were adopted from the Wechsler Adult Intelligence Scale (Wechsler, 2008). Here, participants listened to a series of numerical digits which they had to recall as a series in regular or reverse order. All working memory scores were z-transformed and averaged to obtain a single compound working memory score (z-score).
Temporal discounting task
Participants performed 140 trials of a temporal discounting task where on each trial they made a choice between a smaller-but-sooner (SS) immediate reward, and a larger-but-later (LL) reward delivered after a specific delay. SS and LL rewards were randomly displayed on the left and right sides of the screen, and participants were free to make their choice at any time. While SS rewards were held constant at 20€. LL rewards were computed as multiples of the SS reward (task version 1: 1.05, 1.055, 1.15, 1.25, 1.35, 1.45, 1.55, 1.65, 1.85, 2.05, 2.25, 2.55, 2.85, 3.05, 3.45, 3.85; task version 2: 1.025, 1.08, 1.2, 1.20, 1.33, 1.47, 1.5, 1.70, 1.83, 2.07, 2.3, 2.5, 2.80, 3.10, 3.5, 3.80. Each LL reward from one version was then combined with each delay option for this version (in days): (either: 1, 7, 13, 31, 58, 122, or v: 2, 6 15, 29, 62, 118) yielding 140 trials in total. The mean larger LL magnitude was the same across task versions and the order was counterbalanced across subjects and session (neutral/gambling).
At the end of each session, one decision was randomly selected and paid out in the form of a gift certificate for a large online store, either immediately (in the case of an SS choice) or via email/text message after the respective delay (in the case of a LL choice).
2-step task
Participants performed a slightly modified version of the 2-step task, a sequential reinforcement learning paradigm (). Based on more recent suggestions () we modified the outcome stage by replacing the fluctuating reward probabilities (reward vs. no reward) with fluctuating reward magnitudes (Gaussian random walks with reflecting boundaries at 0 and 100, and standard deviation of 2.5). In total the task comprised 300 trials. Each trial consisted of two successive stages: In the 1st stage (S1), participants chose between two fractals embedded in grey boxes. After taking an S1 action, participants transitioned to one of two possible 2nd stages (S2) with fixed transition probabilities of 70% and 30%. In S2, participants chose between two new fractals each providing a reward outcome in points (between 0–100) that fluctuated over time. To achieve optimal performance, participants had to learn two aspects of the task. They had to learn the transition structure, that is, which S1 stimulus preferentially (70%) leads to which pair of S2 stimuli. Further, they had to infer the fluctuating reward magnitudes associated with each S2 stimulus.
In both versions, the tasks differed in the S1 and S2 stimuli, and in the fluctuating rewards in S2. However both task versions reward walks were equal in variance and mean, that is version 2 walks were simply just version 1 walks in reverse. Both versions were presented in counterbalanced order per session (neutral/gambling). Participants were instructed about the task structure and performed 40 practice trials (with different random walks and symbols) at the first appointment (Baseline screening). Following task completion, points (*0.25) were converted to € and participants could win a bonus of up to 4.50€ that was added to the baseline reimbursement of 10€/h.
Computational modeling and Statistical Analysis
Temporal discounting model
We applied a single-parameter hyperbolic discounting model to describe how subjective value changes as a function of LL reward height and delay (Mazur, 1987; Green and Myerson, 2004):

Here, At is the reward height of the LL option on trial t, Dt is the LL delay in days on trial t and It is an indicator variable that takes on a value of 1 for trials from the gambling context and 0 for trials from the neutral condition. The model has two free parameters: k is the hyperbolic discounting rate (modeled in log-space) and sk is a weighting parameter that models the degree of change in discounting in the gambling compared with the neutral context condition.
Softmax action selection
Softmax action selection models choice probabilities as a sigmoid function of value differences (Sutton and Barto, 1998):

Here, SV is the subjective value of the larger but later reward according to Eq. 1 and β is an inverse temperature parameter, modeling choice stochasticity (for β = 0, choices are random and as β increases, choices become more dependent on the option values). SV(SSt) was fixed at at 20 and It is again the dummy-coded context regressor, and sb models the context effect on β.
Temporal discounting drift diffusion models
To more comprehensively examine environmental effects on choice dynamics, we additionally replaced softmax action selection with a series of drift diffusion model (DDM)-based choice rules. In the DDM, choices arise from a noisy evidence accumulation process that terminates as soon as the accumulated evidence exceeds one of two response boundaries. In the present setting, the upper boundary was defined as selection of the LL option, whereas the lower boundary was defined as selection of the SS option.
RTs for choices of the SS option were multiplied by –1 prior to model fitting. We furthermore used a percentile-based cut-off, such that for each participant the fastest and slowest 2.5 percent of trials were excluded from the analysis. We then first examined a null model (DDM0) without any value modulation. Here, the RT on each trial t (t ϵ 1:140) is distributed according to the Wiener First Passage Time (wfpt):

The parameter α models the boundary separation (i.e. the amount of evidence required before committing to a decision), τ models the non-decision time (i.e., components of the RT related to motor preparation and stimulus processing), z models the starting point of the evidence accumulation process (i.e., a bias towards one of the response boundaries, with z>.5 reflecting a bias towards the LL boundary, and z<.5 reflecting a bias towards the SS boundary) and ν models the rate of evidence accumulation. Note that for each parameter x, we also include a parameter sx that models the change in that parameter from the neutral context to the gambling context (coded via the dummy-coded condition regressor It).
As in previous work (; ; , ), we then set up temporal discounting drift diffusion models with trial-wise modulation of drift rates by the difference in subjective values between choice options. First, we set up a version with linear modulation of drift-rates (DDMlin) ():

Here, the drift rate on trial t is calculated as the scaled value difference between the subjective LL and SS rewards. Thus, we substituted the v+s_υ*I_t term within Eq. 3 with v_t (Eq. 4). As noted above, RTs for SS options were multiplied by –1 prior to model estimation, such that this formulation predicts more SS choices whenever SV(SS)>SV(LL) (the trial-wise drift rate is negative), and predicts longest RTs for trials with the highest decision-conflict (i.e., in the case of SV(SS)= SV(LL) the trial-wise drift rate is zero). We next examined a DDM with non-linear trial-wise drift rate scaling (DDMS) that has recently been reported to account for the value-dependency of RTs better than the DDMlin (; ; ). In this model, the scaled value difference from Eq. 4 is additionally passed through a sigmoid function with asymptote vmax:


All parameters including vcoeff and vmax were again allowed to vary according to the context, such that we included sx parameters for each parameter x that were multiplied with the dummy-coded condition predictor It.
Reinforcement Learning model
Hybrid model
We first applied a slightly modified version of the hybrid RL model () close to the extension of Otto et al. () to analyze the strength of model-free and model-based RL strategies. In detail we applied the following changes in comparison to the model of Otto et al. (): Value updating via standard prediction error schemes in stages S1 and S2 instead of rescaled PEs (by 1/α). Further, updating included two separate learning rates instead of one single learning rate for both stages. The eligibility trace parameter was set to one and all values from unchosen options for both stages were set to decay towards the reward walks’ mean (i.e. 50 points) as proposed by Toyama et al. (, ). These model extensions were validated with data from a separate, to date unpublished study, acquired previously. In detail, the model updates MF state-action values (QMF-values, Eq. 7, 8) in both stages through prediction errors (Eq. 9, 10). In stage 1, MB state-action values (QMB) are then computed from the transition and reward estimates using the Bellman Equation (Eq. 11).

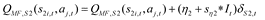



Here, i indexes the two different second stages (S21, S22), j indexes actions a (a1, a2) and t indexes the trials. Further, η1 and η2 denote the learning rate for S1 and S2, respectively. S2 MF Q-values are updated by means of reward (r2,t) prediction errors (δS2,t) (Eq. 8, 10). To model S1 MF Q-values we allow for reward prediction errors at the 2nd-stage to influence 1st-stage Q-values (Eq. 7, 9).
In addition, as proposed by Toyama et al. (, ) Q-values of all unchosen stimuli were assumed to decay with decay-rate ηdecay and centered to the mean of reward walks (0.5). A decay of Q-values over time accounts for the fact that participants know that reward walks fluctuate over time. The decay was implemented according to Eq. 12 and 13:

where

and K ∈ {1, 21, 22}, that is, k indexes the three task stages.
S1 action selection is then modelled via weighting S1 MF and MB Q-values through a softmax action-selection. S2 stage action selection is likewise modelled as a function of MF Q-value differences. Separate ‘inverse temperature’ parameters β model subjects’ weights of MF and MB Q-Values (Eq. 14 and Eq. 15). The additional parameter ρ captures 1st-stage choice perseveration, and is set to 1 if the previous S1 choice was the same and is zero otherwise.


where:
βMBs = βMB + SβMB * It
βMFs = βMF + SβMF * It
ρs = ρ + Sρ * It
β2s = β2 + Sβ2 * It
Hybrid model with drift diffusion action selection
As in our analysis of temporal discounting we replaced softmax action selection with a DDM choice rule (), leaving the reinforcement learning equations unchanged. For each stage of the task, the upper boundary was defined as selection of one stimulus, whereas the lower boundary was defined as selection of the other stimulus. We modelled each stage of the task using separate non-decision time (τ), boundary separation (α) and drift- rate (v) parameters. The bias (z was fixed to 0.5. All parameters including vcoeffMF, vcoeffMB and vmax were again allowed to vary according to the context, such that we included sx parameters for each parameter x that were multiplied with the dummy-coded condition predictor It (see above).
Data were filtered using a percentile-based cut-off, such that for each participant the fastest and slowest 2.5 percent of RTs/trials were excluded from further analysis. In addition, trials with RTs < 150ms were excluded. We then first examined a null model (DDM0; Eq. 3) without any value modulation followed by two value-informed models where the drift-rate (v) is a linear (Eq. 16 and 17) or sigmoid (Eq. 18) function of MF and MB Q-value weights. For the linear version, the drift rate in S1 is

and the drift rate in S2 is calculated as

For the non-linear version, the linear drift rate from equations 16 and 17 are additionally passed through a sigmoid:

where
vcoeffMBs = vcoeffMB + svMB * It
vcoeffMFs = vcoeffMF + svMF * It
vcoeffS2s = vcoeffS2 + sS2 * It
vmaxSis = vmaxSi + sSi * It
Hierarchical Bayesian models
Softmax models were fit to all trials from all participants using a hierarchical Bayesian modeling approach with separate group-level distributions for all baseline parameters for the neutral context and shift parameters (sx) for the gambling context.
For the intertemporal choice data, model estimation was performed using Markov Chain Monte Carlo (MCMC) sampling as implemented in the JAGS (Version 4.3) software package () in combination with the Wiener module (Wabersich and Vandekerckhove, 2014). Model estimation was done in R (Version 4.0.3) using the corresponding R2Jags package (Version 0.6-1). For baseline group-level means, we used uniform priors defined over numerically plausible parameter ranges (see code and data availability section for details). For all sx parameters modeling context effects on model parameters, we used Gaussian priors with means of 0. For group-level precisions, we used gamma distributed priors (.001, .001). We initially ran 2 chains with a varying burn-in period and thinning of two until convergence. Chain convergence was then assessed via the Gelman-Rubinstein convergence diagnostic Rˆ and sampling was continued until 1 ≤ Rˆ ≤ 1.02 for all group-level and individual-subject parameters. 20k additional samples were then retained for further analysis.
For the 2-step task, model estimation was performed using MCMC sampling as implemented in STAN () via R (Version 4.0.3) and the rSTAN package (Version 2.21.0).
For baseline group-level means, we used uniform and normal priors defined over numerically plausible parameter ranges (see code and data availability section for details). For all sx parameters modeling context effects on model parameters, we used Gaussian priors with means of 0. For group-level standard deviations we used cauchy (0, 2.5) distributed priors. We initially ran 2 chains with a burn-in period of 1000 and retained 2000 samples for further analysis. Chain convergence was then assessed via the Gelman-Rubinstein convergence diagnostic Rˆ and sampling was continued until 1 ≤ Rˆ ≤ 1.02. This threshold was not met for one participant (Rˆ < 1.4).
For both tasks, relative model comparison was performed via the loo-package in R (Version 2.4.1) using the Widely-Applicable Information Criterion (WAIC) where lower values reflect a superior fit of the model (). We then show posterior group distributions for all parameters of interest as well as their 85% and 95% highest density intervals. For group comparisons we report Bayes Factors for directional effects for sx hyperparameter distributions of sx > 0 (gambling context > neutral context), estimated via kernel density estimation using R via the RStudio (Version 1.3) interface. These are computed as the ratio of the integral of the posterior difference distribution from 0 to +∞ vs. the integral from 0 to -∞. Using common criteria (Beard et al. 2016), we considered Bayes Factors between 1 and 3 as anecdotal evidence, Bayes Factors above 3 as moderate evidence and Bayes Factors above 10 as strong evidence. Bayes Factors above 30 and 100 were considered as very strong and extreme evidence respectively, whereas the inverse of these reflect evidence in favor of the opposite hypothesis.
Posterior Predictive checks
We carried out posterior predictive checks to examine whether models reproduced key patterns in the data, in particular the value-dependency of RTs (; ) and participant’s choices. For the intertemporal choice task, we binned trials of each individual participant into five bins, according to the absolute difference in subjective larger-later vs. smaller-sooner value (“decision conflict”, computed according to each participant’s median posterior log(k) parameter from the DDMS, and separately for the neutral and gambling context. For each participant and context, we then plotted the mean observed RTs as a function of decision conflict, as well as the mean RTs across 10k data sets simulated from the posterior distributions of the DDM0, DDMlin and DDMS. For the 2-step task, we extracted mean posterior parameter estimates and simulated 200 datasets in R (Version 4.0.3) using the Rwiener package (Version 1.3.3). We then show RTs as a function of S2 reward difference of observed data and the mean RTs across 200 simulated datasets for of all DDMs. We further show that our models capture the relationship of S2 reward differences and optimal (max[reward]) choices.
Model free analysis
As a model-agnostic measure of temporal discounting, we performed a logistic regression on choices as a function context (neutral vs. gambling; fixed effect) and subject as random effect. For the 2-step task we likewise use a hierarchical generalized linear model (HGLM) and modeled 2nd-stage RTs as a function of transition (common vs. rare) and context (neutral vs. gambling) as fixed and subject as random effect. In line with our modelling analyses, data were filtered so that implausibly fast RTs were excluded (see Methods). A standard analysis of stay probabilities () adapted to our task version is reported in the Supplement (Supplemental Table S5).
Subjective Craving Rating
On each testing day, participants rated their subjective craving (“How much do you desire to gamble right now?”) on a visual-analogue scale ranging from 0 to 100, both at the beginning of the testing session, and at the end following task completion. We then used paired t-tests to examine whether subjective craving differed between the testing environments (neutral vs. gambling).
Results
Subjective craving
Craving was assessed on a visual-analogue-scale before and after task performance. Due to technical problems, ratings of the first eight participants were lost. Another two participants did not complete post-task ratings. In the remaining n = 22 participants, craving was substantially higher in the gambling-related environment compared to the neutral environment (paired t-test pre-task: t23 = –3.13; p = 0.0048, Cohen’s d: 0.75; post-task: t21 = –4.32, p = 0.0003, Cohen’s d = 0.68; see Figure 1).
Subjective craving was assessed at the beginning (A) and at the end (B) of each testing session via a visual-analogue scale rating. Craving was significantly higher in the gambling environment, both at the start of the session (p = 0.0048) and at the end of the session (p = 0.0003).
Temporal discounting
Model-agnostic analysis temporal discounting task
Raw proportions of larger-but-later (LL) choices are plotted in Figure 2A for each context. A logistic regression on choices with context (gambling vs. neutral) as a fixed effect and subject as random effect confirmed a significant main effect of context (βcontex = –0.52; z = –10.62, p < 0.0001) such that participants made more LL selections in the neutral vs. the gambling-related environment. Overall response time (RT) distributions are plotted in Figure 2B with choices of the LL option coded as positive RTs and choices of the smaller-sooner option coded as negative RTs.
Behavioral data from the temporal discounting task. A: raw proportions of larger-later (LL) choices in each context. B: Overall response time distributions with choices of the LL option coded as positive RTs and choices of the smaller-sooner option coded as negative RTs; Note, this was done to add choice coding to the computational model.
Softmax choice rule
We first modeled the data using standard softmax action selection. This analysis revealed an overall context effect on log(k), such that discounting was substantially steeper in the gambling context compared to the neutral context (Figure 3B, 95% HDI > 0). Examination of Bayes Factors indicated that an increase in log(k) in the gambling context (sk) was about 116 times more likely than a decrease (see Figure 3 and Table 3). There was no evidence for a change in choice stochasticity (softmax[β]; Figure 3C/D).
Softmax model; Posterior distributions of mean hyperparameter distributions for the neutral baseline context (blue) and the corresponding shift in the gambling context (pink). A, discount-rate log (k); B, shift in discount-rate (sk); C, softmax β; D, shift in softmax β; Thin (thick) horizontal line denote 95% (85%) highest posterior density intervals.
Temporal discounting drift diffusion models (DDMs)
Model comparison of temporal discounting DDMs revealed the same model ranking in each context (Supplemental Table S3) such that the data were best accounted for by a temporal discounting DDM with non-linear drift rate scaling. This model accounted for around 90% of decisions (Supplemental Table S4, Supplemental Figure S1) and posterior predictive checks confirmed that it reproduced individual-participant RTs (Supplemental Figure S2).
We next examined the posterior distributions of model parameters of the best-fitting TD-DDM model (DDMs with sigmoid drift rate scaling; we further report model comparison, binary choice predictions and posterior predictive checks in the corresponding Model comparison and validation section in the supplement). Results are plotted in Figure 4 and Figure 5 and Bayes Factors for all context-effects are listed in Table 1. There was a consistent positive association between trial-wise drift rates and value differences in the neutral context (Figure 4E, the 95% HDI for the drift rate coefficient parameter did not include 0). Likewise, there was a numerical bias towards the smaller-sooner option in the baseline condition (85% HDI < 0.5, see Figure 4F). The non-decision time was numerically smaller in the gambling context (85 % HDI < 0, Figure 5B, Table 1), amounting to on average a 50ms faster non-decision time. The maximum drift-rate was substantially higher in the gambling context (95% HDI > 0, Figure 5D).
Temporal discounting drift diffusion model results: posterior distributions for hyperparameter means from the neutral context. A: discount-rate log(k), B: non-decision time τ, C: boundary separation α, D: maximum drift-rate vmax, E: drift-rate coefficient vcoeff, F: starting-point z. Thin (thick) horizontal line denote 95% (85%) highest posterior density intervals.
Table 1
Overview of overall context differences. For group comparisons we report Bayes Factors for directional effects for sx hyperparameter distributions of sx > 0 (gambling context > neutral context).
| MODEL PARAMETER (CHANGE IN GAMBLING CONTEXT) | SOFTMAX MODEL | DDMS | ||
|---|---|---|---|---|
| MEAN | dBF | MEAN | dBF | |
| sk (discount-rate) | 0.77 | 1688.53 | 0.40 | 54.20 |
| sβ (softmax beta) | 0.025 | 2.27 | – | – |
| svcoeff (drift-rate coeff.) | – | – | –0.012 | 0.25 |
| sτ (non-decision time) | – | – | –0.05 | 0.10 |
| sα (boundary separation) | – | – | 0.10 | 4.40 |
| sz (starting point bias) | – | – | 0.02 | 13.64 |
| svmax (max drift-rate) | – | – | 0.33 | 39490.71 |
Temporal discounting drift diffusion model results: posterior distributions for hyperparameter means for context shift (sx) parameters modeling changes from the neutral to the gambling context. A: shift in discount-rate (sk), B: shift in non-decision time sτ, C: shift in boundary separation sα, D: shift in maximum drift-rate vmax, E: shift in drift-rate coefficient vcoeff, F: shift in starting-point sz. Thin (thick) horizontal line denote 95% (85%) highest posterior density intervals.
As in the softmax model (Figure 3), we observed a substantial increase in the discount rates log(k) in the gambling context (95% HDI > 0, see Figure 5A, Table 1).
Temporal discounting and gambling-related questionnaire data
As preregistered, we next examined whether the increased in discount-rate sk in the gambling context was associated with symptom severity or gambling related cognition. We therefore computed a compound symptom severity z-score of DSM-5 (), SOGS () and KFG () scores. Gambling context-related changes in temporal discounting were not significantly associated with symptom severity (ρ = –0.05, p = 0.78) but were positively associated with the total score of the Gambling Related Cognition Scale () (ρ = 0.39; p = 0.03); see Figure 6A). There were no significant correlations between changes in craving and changes in discounting or working memory capacity and temporal discounting (Supplemental Results 1). In line with the suggestion by one Reviewer, we also examined whether a full Bayesian model could capture the relationship of GRCS scores and shift in discount-rate (sk). We thus modelled the gambling context related shift in the discount-rate as a linear combination of both GRCS total scores and the gambling symptom severity compound score (see Figure 6B and C). This revealed strong evidence for a positive effect of GRCS total scores on sk, the change in log(k) (95% HDI > 0; dBF = 37.81).
A: Pre-registered correlation of the gambling context related shift in log(k) (median values) and total gambling-related cognition score (GRCS) [softmax model]. B, C: Posterior distributions of effects of GRCS total score (B) and a gambling symptom severity compound score across DSM criteria, KFG and SOGS scores (C) on change in log(k). Plots B and C are from an extended model, in which these covariates were included in the full hierarchical Bayesian model.
2-step reinforcement learning task
Model-agnostic analysis 2-step task
Participants earned significantly more points in the gambling context (t-test: t28 = –2.44, p = 0.02, Cohen’s d = 0.22). For S2 RTs, we observed a significant main effect of transition (Supplemental Table S7 and Supplemental Figure S3) and a trend for a transition x context interaction (p = 0.07; see Supplemental Table S7), reflecting increased model-based control (; ).
An analysis of stay probabilities adapted to the present 2-step task version is shown in Supplemental Table S5. In each context, we observed main effects of reward (reflecting model-free RL) and reward x transition interaction (reflecting model-based RL). The reward x transition x context interaction was not significant.
Hybrid model with softmax choice rule
We first examined a modified version of the hybrid model () using a standard softmax choice rule (see Methods for details; Figure 7). This model included separate parameters for S1 and S2 learning rates, model-free and model-based β weights for S1 and a β weight for S2 Q-value differences. We confirmed substantial contributions of both MB and MF values to S1 choices (Figure 7B,C). There was an increase in the S2 learning-rate η (95% HDI > 0, Figure 7F) in the gambling context. Furthermore, there was a strong decrease in MF β weights (95% HDI < 0, Figure 7H) such that participants showed substantially less MF behavior in the gambling environment compared to the neutral environment. BFs for directional effects indicate that an increase in MB reinforcement learning is 4 times more likely than a decrease. For examination of Bayes Factors see Table 2.
Hybrid model with softmax choice rule posterior distributions (top row: neutral context, bottom row: parameter changes in gambling context) of all group level means. A, S1 and S2 learning-rates. B, MB β weight. C, MF β weight. D, S2 β weight. E, perseveration parameter ρ. F, shift in S1 and S2 learning rates. G, shift in MB β. H, shift in MF β. I, shift in S2 β. J, shift in stickiness parameter ρ. Thin (thick) horizontal line denote 95% (85%) highest posterior density intervals.
Table 2
Overview of overall context differences. For context comparisons we report Bayes Factors for directional effects for sx hyperparameter distributions of sx > 0 (gambling context > neutral context).
| MODEL PARAMETER (SHIFT) | SOFTMAX MODEL | DDMS | ||
|---|---|---|---|---|
| MEAN | dBF | MEAN | dBF | |
| sηS1 (learning-rate S1) | 0.44 | 3.29 | 0.0801 | 1.186 |
| sηS2 (learning-rate S2) | 0.40 | 92.3 | 0.280 | 14.658 |
| sτS1 (non-decision times S1) | – | – | 0.001 | 0.8454 |
| sτS2 (non-decision times S2) | – | – | 0.001 | 1.161 |
| sρ (Stickiness S1) | 0.04 | 1.946 | 0.05 | 2.365 |
| sαS1 (boundary separation S1) | – | – | –0.002 | 0.9354 |
| sαS2 (boundary separation S2) | – | – | 0.0149 | 2.026 |
| βMF/SvcoeffMF (MF beta/drift-rate coeff.) | –1.14 | 0.010 | –0.93 | 0.083 |
| βMB/SvcoeffMB (MB beta/drift-rate coeff.) | 1.08 | 4.00 | 4.01 | 169.62 |
| βS2/SvcoeffS2 (S2 beta/drift-rate coeff.) | –0.44 | 0.428 | –0.64 | 0.271 |
| svmaxS1 (max drift-rate S1) | – | – | –0.19 | 0.296 |
| svmaxS2 (max drift-rate S2) | – | – | 0.41 | 15.83 |
Hybrid model with drift diffusion choice rule
We next combined the hybrid model with a DDM choice-rule () and likewise compared DDMs that varied in the way that they accounted for the influence of Q-value differences on trial-wise drift rates in both task stages. Model comparison yielded the same model ranking in each context, such that the data were best accounted for by an RLDDM with non-linear drift rate scaling (Supplemental Table S8). This model accounted for around 73% of S1 choices, and around 81% of S2 choices (Supplemental Table S9). Posterior predictive checks confirmed that this model reproduced the observed RTs (Supplemental Figure S4) and choice proportions (Supplemental Figure S5).
Posterior distributions for the best-fitting RLDDM are shown in Figure 8 (neutral context parameters) and Figure 9 (gambling context changes). We observed positive associations between trial-wise drift rates and Q-value differences (Figure 8F-J, all 95% HDIs above 0). Likewise, as in the softmax model, beta weights were positive, indicating contributions of both MB and MF to behavior (Figure 8E-G, all 95% HDIs > 0). In the gambling context, we observed a decrease in the MF component (85% HDI < 0) and a robust increase in MB contributions (95% HDI > 0). BFs for directional effects are provided in Table 2. Overall, these results suggest decreased MF and increased MB reinforcement learning due to gambling context exposure.
RL-DDM. Posterior distributions of all hyperparameters for the neutral baseline condition. A: S1 and S2 learning rates η. B: S1 and S2 non-decision time τ. C: S1 and S2 boundary separation α. D: S1 and S2 drift-rate maximum vmax. E: MF drift-rate coefficient vcoeffMF. F: MB drift-rate coefficient vcoeffMB. G: S2 drift-rate coefficient vcoeffS2. H: stickiness parameter ρ. Thin (thick) horizontal line denote 95% (85%) highest posterior density intervals.
RL-DDM. Posterior distributions of all shift-hyperparameters modelling the change the change from neutral to gambling condition. A, shift in Stage 1 and Stage 2 learning rates η. B, shift in S1 and S2 non-decision time τ. C, shift in S1 and S2 boundary separation α. D, shift in S1 and S2 drift-rate maximum vmax. E, shift in S1 MF drift-rate coefficient vcoeffMF. F, shift in S1 MB drift-rate coefficient vcoeffMB. G, shift in S2 drift-rate coefficient vcoeffS2. H, shift in stickiness parameter ρ. Thin (thick) horizontal line denote 95% (85%) highest posterior density intervals.
Reinforcement learning and gambling-related questionnaire data
As preregistered, we examined associations between ρ (perseveration) and gambling symptom severity (average z-score across SOGS (), KFG () and DSM-5 criteria). The association was non-significant ρ (r = –0.10, p = 0.59). There were no significant correlations between changes in craving and changes in MB behavior, nor between MB behavior and working memory capacity (Supplemental Results 2). In an exploratory analysis we found that gambling symptom severity (average z-score across DSM, KFG and SOGS) was associated with a greater gambling context related decrease in MF drift-rate weights (r = –0.48, p = 0.009; see Supplemental Figure S6A). There was no association of gambling symptom severity and the context related increase of MB drift-rate weights (see Supplemental Figure S6B).
Discussion
Here we comprehensively examined the contextual modulation of two putatively trans-diagnostic markers implicated in addiction, temporal discounting (; ) and model-based control (; ) in a pre-registered study. We studied regular slot machine gamblers, a group previously characterized by high levels of temporal discounting () and reduced model-based control (). Following a seminal study by Dixon et al. (), regular gamblers were tested in gambling environments (slot-machine venues) and neutral control environments. Gambling cue exposure modulated temporal discounting and model-based control in gamblers in opposite ways: replicating Dixon et al., (), discounting substantially increased in a gambling context. In contrast, model-based (MB) control improved (increased). This differential modulation of two prominent trans-diagnostic traits in (behavioral) addiction has important theoretical and clinical implications.
Theoretical accounts highlight the central role of addiction-related cues and environments in drug addiction (). Similar mechanisms have been suggested to underlie gambling disorder (). Because terrestrial slot machine gambling is directly linked to specific locations, gambling disorder is uniquely suited to investigate the impact of cue exposure on behavior. We replicated the finding of Dixon et al. () of steeper discounting in gambling vs. neutral environments in gamblers. This effect was observed across model agnostic analyses (proportion of LL choices) and computational modeling (softmax, drift diffusion models [DDM]). We additionally extended these earlier results in the following ways. First, we observed an association of this effect with maladaptive control beliefs (GRCS) () suggesting that such beliefs contribute to increased temporal discounting in gambling environments. These gambling-related cognitions correspond to beliefs, ideas, urges and intentions associated with gambling. They were originally identified while asking gamblers to comment on their thoughts and intentions while gambling (“speaking out loud method”) (). The GRCS scale captures these erroneous cognitions using five subscales corresponding to e.g. illusionary control over outcomes, understanding gambling machines i.e. predicting outcomes or reframing losses when unsuccessful [for details see ()]. Second, in a subset of participants, we confirmed that exposure to gambling environments substantially increases subjective craving. Third, comprehensive modeling via DDMs revealed additional effects on latent decision processes. The gambling context-related attenuation in non-decision time mirrors previous effects of pharmacological enhancement of dopamine transmission (). In contrast to these earlier pharmacological results, we observed a substantial increase in maximum drift rate (Vmax) in the gambling context, reflecting increased value sensitivity of RTs. Lastly, our results complement cue-reactivity designs showing increased impulsive and/or risky choice in gamblers during exposure to gambling cues in laboratory studies (; ; ). However, effect sizes during naturalistic cue exposure (e.g. the present study and ) were substantially larger than during lab-based exposure in these previous studies.
In addition to temporal discounting, we included a 2-step sequential decision-making task designed to dissociate model-based (MB) from model-free (MF) contributions to behavior (). Reductions in MB control are associated with compulsivity-related disorders (; ; ). We observed increased MB learning and reduced MF learning in gamblers in the gambling context, a pattern of results consistent between softmax and DDM models. These findings were again corroborated by model-agnostic analyses. First, participants earned more points in the gambling context, an effect linked to MB learning (). Second, the slowing of RTs following rare transitions, an indirect measure for MB learning () tended to be more pronounced in the gambling vs. neutral context. Likewise, the increased S1 RTs after greater S2 reward in the gambling context indicated increased response caution in the following S1 choice in the gambling context. A finding that make sense if MB control is enhanced, because participants carefully evaluate their next action. The MF effect correlated with gambling symptom severity in an exploratory analysis, such that higher symptom severity was associated with a greater reduction in MF reinforcement learning in the gambling context. Together, these findings converge on the picture of decreased MF and increased MB control in gamblers when tested in gambling-related environments.
The latter result contrast with our pre-registered hypothesis of reduced MB control, which was based on findings of reduced MB control in populations with extensive habit formation (; ; V. Voon et al., 2015b). Addiction is likewise thought to be inherently associated with pathological habits (; ) which are thought to be triggered by exposure to environmental cues (). We thus hypothesized gambling environments would likewise trigger increased MF behavior and reduced MB behavior on the 2-step task. However, critics of habit theory have emphasized that addiction might in contrast be associated with excessive goal-directed behavior, in particular in the presence of addiction-related cues (). Our findings are more in line with this latter perspective. This interpretation is compatible with incentive sensitization theory (; ), which proposes that addiction-related environments exert their influence on behavior in part via a potentiation in dopamine release (; ; ). Earlier studies observed increased MB control following increases in DA neurotransmission (; ), which could contribute to the present findings regarding 2-step task performance. Furthermore, our results are compatible with decreased MF control under L-Dopa (). The gambling context might thus enhance goal-directed control via an improved construction and/or utilization of the task transition structure. This interpretation further resonates with other perspectives on DA function including a regulation of outcome sensitivity or precision (; ), or the general motivation to exert (cognitive) effort (). The observed increase in S2 learning rates could likewise be mediated in part by increases in DA transmission ().
If the effects of gambling environments on 2-step task performance are (at least in part) driven by increases in DA, then the question arises why gamblers at the same time exhibited substantially increased temporal discounting. The literature on DA effects on temporal discounting is a mixed bag () with some studies showing reduced discounting (; ), some increased discounting () and others suggesting baseline-dependent effects ().
Given that DA was neither measured nor directly manipulated here, these issues cannot be directly resolved. However, our data might nonetheless provide some insights. Effects of DA on decision-making might depend on both task and context (). Under this view, DA signals average reward in the environment (context) and its effects on performance further differ as a function of task controllability [see () for details]. DA might thus facilitate cognitive control (; ) when cognitive effort requirements are high, and there is control over the outcome (e.g. 2-step task). In contrast, DA might facilitate impulsive choice for cognitively less demanding tasks (e.g. temporal discounting task) that are performed in an addiction-related context (; ) signaling high reward (). A further mechanism known to modulate temporal discounting is episodic future thinking or future prospection (; ). Future prospection has been shown to attenuate temporal discounting in a range of settings () and might be attenuated at gambling venues. Participants might be generally focused on the present in the presence of cues or contexts endowed with high levels of incentive salience ().
Our results show that two prominent (potentially trans-diagnostic) computational processes, temporal discounting and MB control, are differentially modulated by addiction-related environments in regular slot machine gamblers. This provides a computational psychiatry perspective on factors that contribute to the understanding of this disorder. The substantial contextual effects on temporal discounting further highlight the potential clinical relevance of this process (; ). Gambling disorder is reliably associated with increased temporal discounting (; ; ; ; ). This trait-like behavior then appears to be further exacerbated during exposure to gambling-related environments, potentially contributing to the maintenance of maladaptive behavior. In contrast, MB control improved (increased) in a gambling context, despite the fact that an earlier study reported reduced MB control in gamblers (). In general these findings are further compatible with a greater tendency for pattern matching () or enhanced cause-effect associations that might translate into increased MB control () and studies suggesting that DA increases the willingness to spend cognitive effort (; ). 2-step task transitions are not random, but can be learned and exploited. An increased tendency to seek for patterns during gambling context exposure might facilitate this behavior. Our findings suggest that gamblers do generally show MB control, which contrasts in parts with one recent study (). This is supported by the robust RTs increases observed following rare transitions (Supplemental Table S7, Supplemental Figure S3) and the positive MB parameters observed across models, somewhat contrasting with the findings of Wyckmans et al. (), although different 2-step task versions have been used in these studies.
We also extended previous studies on this topic via a recent class of value-based decision models based on the DDM (; ; ; ; ). Comprehensive RT-based analysis revealed that standard DDM parameters were largely unaffected by context, suggesting that primarily MF and MB contributions to evidence accumulation were affected by gambling environments (Figure 10.). Posterior predictive checks showed that a DDM with non-linear trial-wise drift rate scaling captured the relationship of decision conflict (SS-LL value difference) and RTs, replicating prior findings (; ). We previously reported good parameter recovery of such temporal discounting DDMs (; ).
A number of limitations need to be acknowledged. First, as in the original study () we did not test a non-gambling control group. However, the observed associations between experimental effects and gambling symptom severity/gambling-related cognition (GRCS) suggests that these effects are at least in part driven by the underlying problem gambling symptoms. Second, MB and MF effects in the 2-step task might be affected by the degree to which participants understand the instructions and/or the degree to which they form an adequate model of the task environment (). Participants in our study were well instructed in written and verbal form and completed extensive training trials. Furthermore, due to the counterbalanced exposure, a lack of understanding of task instructions is unlikely to account for the systematic increase in MB control observed in the gambling context. However, this does not rule out the possibility that participants might have (additionally) adopted alternative model-based strategies not captured by our models. Third, MB control might more generally be related to attentional or motivational processes. Thus, gamblers just might be more motivated to perform while in an environment that is associated with reward and motivates them or primes attentive processes. For example, in general incentives can boost 2-step task performance (). Again, due to the lack of control group, it remains an open question of whether MB control in the gambler group as a function of gambling context exposure was increased to a level comparable to or even superior to healthy controls. However, we ensured that mean and variance of reward walks as well as incentives were identical in both contexts. Fourth, although participants were tested in the same venues, the number of customers present varied across participants, affecting e.g. noise levels and auditory gambling cues (slot machine sounds etc.). A trade-off between the control of such variables and ecological validity is unavoidable when testing in naturalistic settings. Finally, DA neurotransmission was obviously not assessed, rendering our interpretation of the effects in terms of the incentive sensitization theory speculative. But the substantial increase in subjective craving supports the idea that cue exposure had subjective effects predicted by incentive sensitization.
To conclude, here we show that two computational trans-diagnostic markers with high relevance for gambling disorder in particular and addiction more generally are modulated in opposite ways by exposure to real gambling environments. Gamblers showed increased temporal discounting in a gambling context, and this effect was modulated by maladaptive control beliefs. In contrast, MB control improved, a finding that posits a challenge for habit/compulsion theories of addiction. Ecologically valid testing settings such as those investigated here can thus yield novel insights into environmental drivers of maladaptive behavior underlying mental disorders.
Data Accessibility Statement
Model code and raw choice data is available on the Open Science Framework: https://osf.io/5ptz9/.
Additional Files
The additional files for this article can be found as follows:
Supplemental InformationSupplemental Tables, Figures and Results. DOI: https://doi.org/10.5334/cpsy.84.s1
Raw choice dataIntertemporal Choice- and 2-Step Task datasets for all participants. DOI: https://doi.org/10.5334/cpsy.84.s2